Этот код выдирает и показывает текущую погоду с главной страницы яндекса и сохраняет результат в файл.
#!/usr/bin/perl -w
sleep (3);
use LWP::UserAgent;
use HTTP::Request;
$url = "http://www.yandex.ru";
$lwp = LWP::UserAgent->new;
$r = HTTP::Request->new(GET => "$url");
$response = $lwp->request($r);
if ($response->is_success)
{
$tmpout = $response->content;
# $tmpout =~ s/agava/zzzz/g;
$_ = $tmpout;
open ($FILE1, ">", "test.html");
print $FILE1 "$1\n" while m/(<div>.*?<\/a><\/div><\/div>)/g;
close $FILE1;
}
else
{
print $response->error_as_HTML;
}
sleep (3);
Полученный файл — кусок html кода, который в браузере будет выглядеть примерно так:
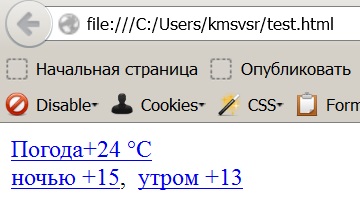 Чтоб допилить под конкретные задачи — можно добавить пару регулярных выражений, чтоб убрать или добавить теги, переписать сохранение файла, например под формат CSV для Excel, ну и добавить сборку ссылок для перебора в цикле, чтоб получился паучок. Можно выгребать например адреса, телефоны, цены и т.п., главное правильно шаблоны составить или в инете готовые найти. Может кому пригодится.
Чтоб допилить под конкретные задачи — можно добавить пару регулярных выражений, чтоб убрать или добавить теги, переписать сохранение файла, например под формат CSV для Excel, ну и добавить сборку ссылок для перебора в цикле, чтоб получился паучок. Можно выгребать например адреса, телефоны, цены и т.п., главное правильно шаблоны составить или в инете готовые найти. Может кому пригодится.